A story of hyper-growth, proactive engineering, and why ThingsBoard Private Cloud is built for the “impossible” peak.
In October, a fast-moving consumer electronics startup approached us. They were successful, ambitious, and sitting on a stable fleet of 5,000 devices. Their platform was running smoothly, but they were about to face the ultimate startup “good problem”: a massive global holiday launch.
Their forecast wasn’t just growth-it was an explosion. They expected to hit 200,000+ devices by Christmas Day.
Christmas Challenge
When IoT devices are popular holiday gifts, Christmas becomes more than just a celebration – it’s a high-traffic event. For a manufacturer of personal devices, December 25th is the day when thousands of “sleeping” devices wake up simultaneously.
The challenge wasn’t just the telemetry traffic – it was the combination of two demanding requirements:
- Encrypted Connections: Every single device was configured with TLS and individual client certificates, utilizing ThingsBoard’s built-in X.509 authentication. While highly secure, this adds significant computational overhead during mass connection events.
- The First-Boot OTA Update: Their custom firmware was designed to request a critical update immediately upon unboxing. This wasn’t a simple download; it triggered a 2MB chunk-based MQTT download for every single device, forcing the platform to coordinate thousands of concurrent file-transfer streams without choking the network.
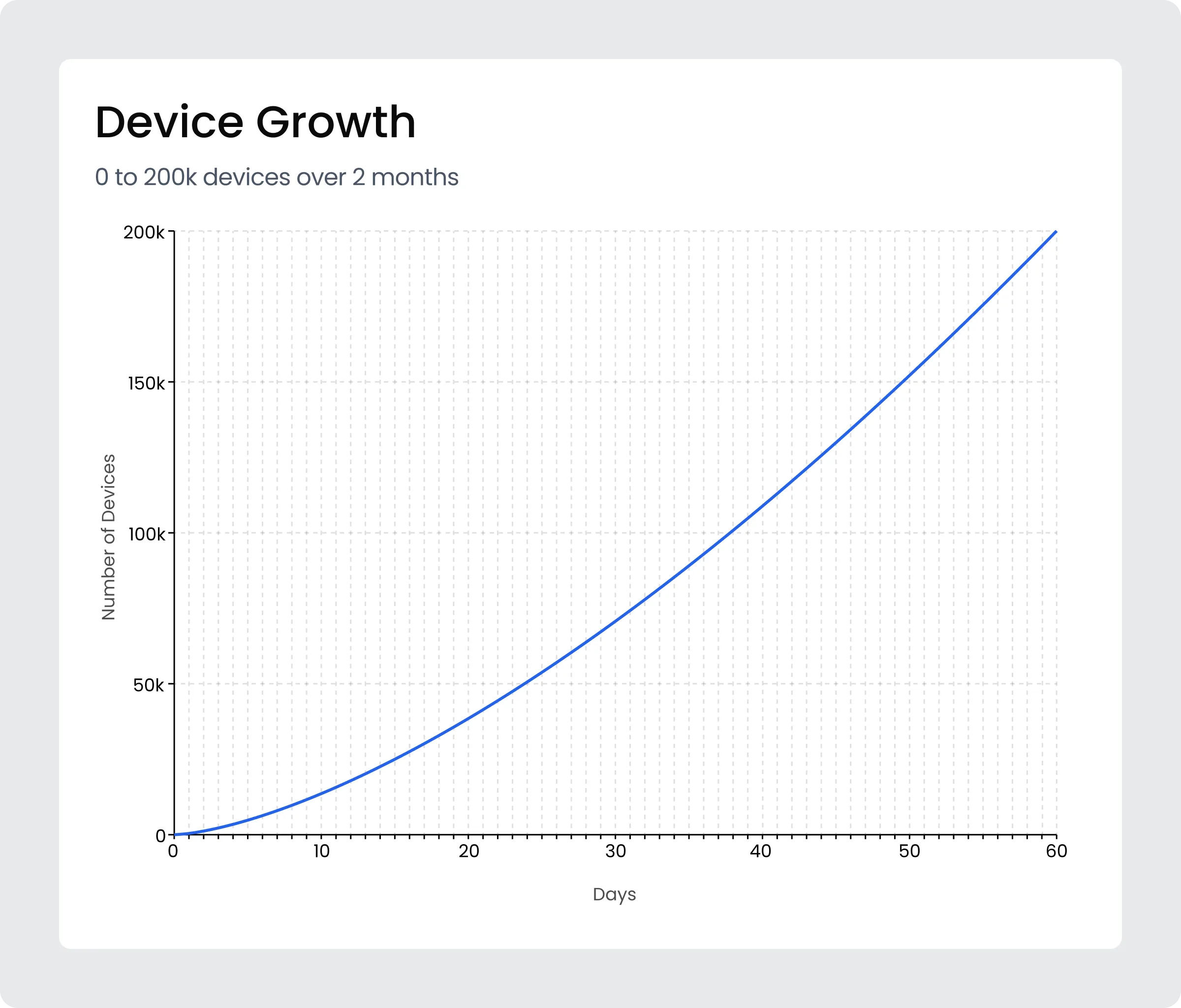
Our standard ThingsBoard Private Cloud environments are tuned and tested to support up to 100,000 devices. However, this startup expected approximately two times that volume to hit the servers within a single 24-hour period.
At this scale, the “standard” setup would face an “Infrastructure Trap”:
- X.509 Handshake Storms: Thousands of CPU-intensive TLS handshakes every second.
- MQTT Chunking Bottlenecks: Managing the delivery of firmware chunks to 200k concurrent requests.
- Core Processing Saturation: The brains of the platform need to verify and route 200k unique certificates and sessions.
Solution Strategy
As ThingsBoard platform contributors, we don’t just “manage” the software – we can work with the source code itself. This gives us the unique ability to deploy hot patches if an edge case arises. While the platform held up perfectly and no emergency patches were needed, our Private Cloud team went into proactive mode to ensure success.
Mirror Cluster Stress Test
We built a twin environment – a perfect replica of their production setup. Using custom scripts, we simulated a “Storm” event: 200,000 devices waking up, authenticating via X.509, and requesting chunk-based OTA updates while simultaneously sending telemetry to the platform. We intentionally exceeded the projected load to ensure sufficient capacity beyond expected demand.
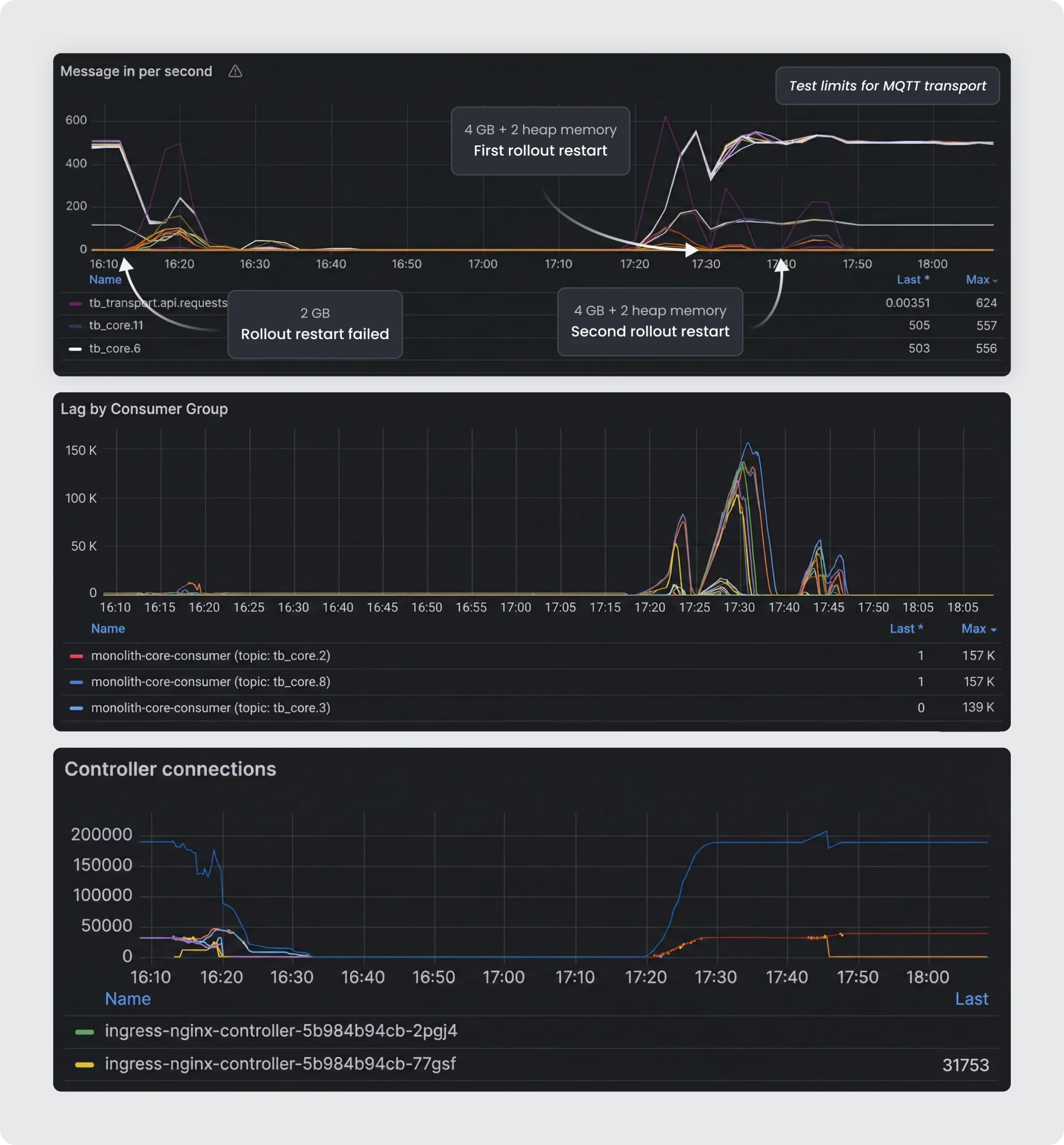
Surgical Scaling
One of the core advantages of the ThingsBoard architecture is the ability to scale individual microservices independently based on specific bottlenecks. We didn’t need to bloat the entire infrastructure; we scaled exactly where the pressure was:
- 6 MQTT Transport Microservices: To handle the massive connections, X.509 handshake, and MQTT traffic.
- 6 Core Microservices: To manage the logic, device authentication, and OTA orchestration.
- 6 Nginx Load Balancers: To ensure the entry point of the cluster never reaches saturation and to achieve balanced traffic distribution between services.
Relying solely on horizontal scaling was insufficient; this scenario also demanded granular fine-tuning of critical configuration parameters to extract maximum performance from each replica. All other infrastructure components remained on our standard Scale Plan settings, proving how efficient ThingsBoard can be when you can tune components on a case-by-case basis.



We rolled out these architectural and configuration changes in early December. While updating the Nginx and MQTT transport configurations required a service restart, we utilized a carefully orchestrated rollout-restart strategy. Existing devices reconnected to the new instances in under one second. Because the transition was so rapid and handled natively by the platform’s load distribution logic, the active devices remained stable, and end users never noticed a flicker of disruption.
December 25th: The Result
While the world was opening presents, our team was in the monitoring room. We watched the dashboards as the “storm” arrived. Tens of thousands of devices began checking in every hour, each verifying its certificate and beginning its firmware download.
The graphs spiked, but the system held perfectly.
- Zero Crashes.
- Zero Lag.
- 99.9944% OTA Success Rate for all authorized devices.
- Proactive Watch: dedicated monitoring during peak hours ensured instant reaction to anomalies.
By the time the holiday season ended, the startup had successfully transitioned from a 5k-pilot to a 200k-device enterprise powerhouse.
The Takeaway
This success story illustrates the fundamental difference between standard hosting and ThingsBoard Private Cloud.
When you operate at enterprise scale, “standard” is rarely enough. ThingsBoard Private Cloud is designed specifically for companies that have outgrown the limits of shared infrastructure and generic DevOps support.
This experience not only provided a stable environment for our client, but it also improved our team and our product. Achieving these results in a short time has cemented our client’s trust in the service we provide and inspired us to seek more innovative solutions for our customers.
When you choose ThingsBoard Private Cloud, you aren’t just buying a license-you are gaining an engineering partner that knows every line of code and stays one step ahead of your business needs.
Is your fleet ready for the next big spike?